Description
In this blog, we will look into the execution flow of hadoop mapreduce job (word count) in detail.
Word count job is simple and straightforward, so it is an good example to show how hadoop is working internally.
We will try to go through the whole lifecycle of the jobs, see how components are interacting by looking into the source codes.
We mainly look into client side logic, resource manager, node manager, application master, and do not look much into the internal of datanode or namenode.
Hadoop source code version is based on 3.3.0-SNAPSHOT, which is the latest at this point.
Understand hadoop RPC
Considering RPC is heavily used in hadoop, so understanding it is important for reading source codes.
There are already many articles written by other people about the hadoop RPC, I will just show one graph about it.
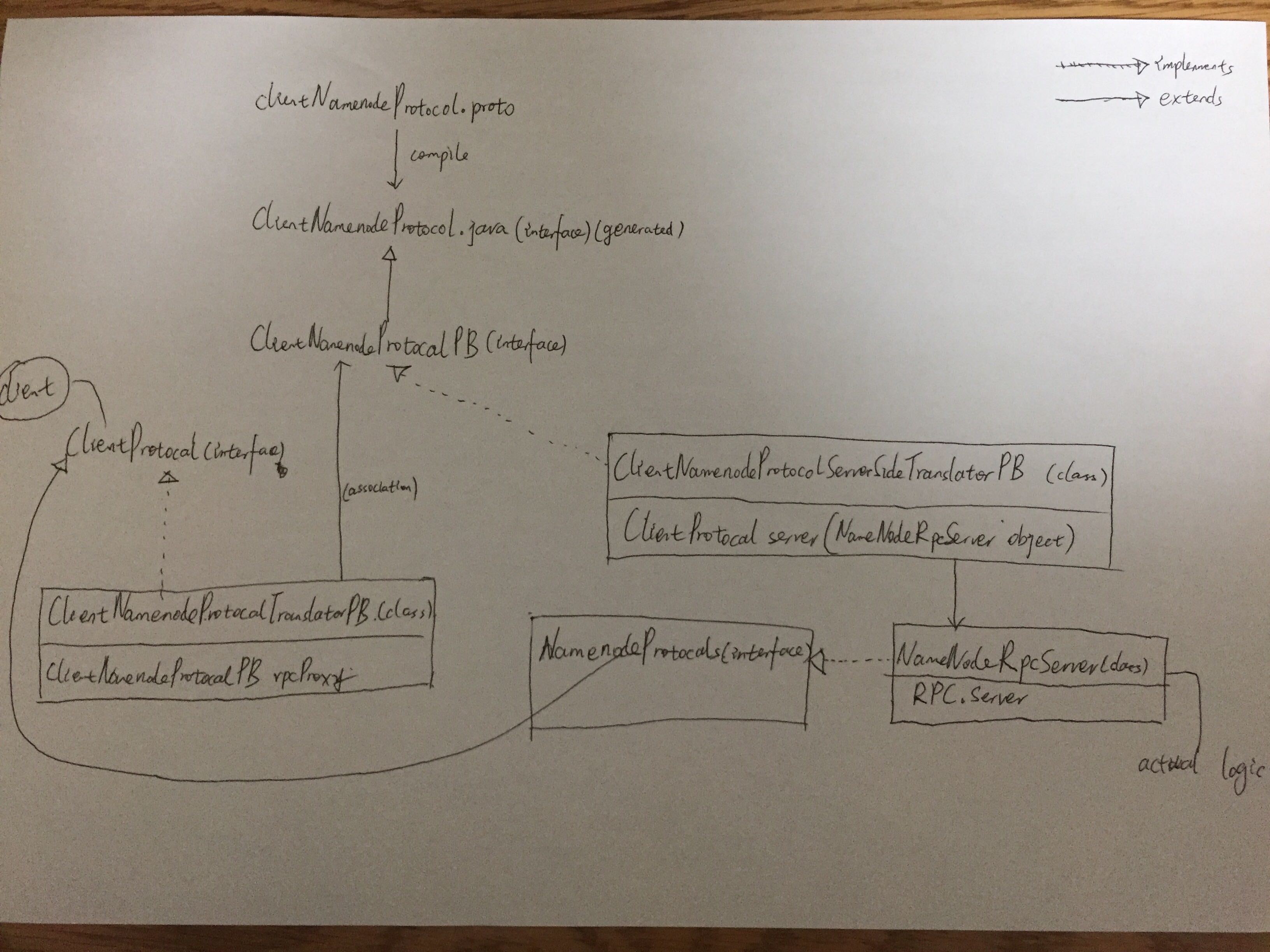
This graph shows the class relationship around namenode client-server RPC call.
As we can see, the protobuffer specification is written in ClientNamenodeProtocal.proto file.
ClientNamenodeProtocal.java is an interface generated from the proto file.
All other classes(in client and server side), contains the functions provided by the ClientNamnodeProtocal interface, either by extends relationship or by associate relationship.
One an api call in invoked, data flow is : ClientNamenodeProtocalTranslatorPB(client side) -> ClientNamenodeProtocalServerSideTranslatorPB(server side) -> NamenodeRpcServer
Job execution flow
Job submission
1 | WordCount(hadoop-mapreduce-examples) |
Resource manager application lifecycle : RMAppState NEW -> NEW_SAVING
1 | State machine : RMAppImpl.StateMachineFactory(hadoop-yarn-server-resourcemanager) |
RMAppState SUBMITTED -> ACCEPTED
1 | RMAppImpl.StartAppAttemptTransition |
RMAppAttemptState NEW -> SUBMITTED
1 | RMAppAttemptImpl.AttemptStartedTransition handles RMAppAttemptEventType.START : RMAppAttemptState NEW -> SUBMITTED |
RMAppAttemptState SUBMITTED -> SCHEDULED
1 | ScheduleTransition handles the RMAppAttemptEventType.ATTEMPT_ADDED event |
RMAppAttemptState SCHEDULED -> ALLOCATED_SAVING
1 | This is not very straightforward. |
RMAppAttemptState ALLOCATED_SAVING -> ALLOCATED
1 | AttemptStoredTransition handles the RMAppAttemptEventType.ATTEMPT_NEW_SAVED event |
RMAppAttemptState ALLOCATED -> LAUNCHED
1 | AMLaunchedTransition handles the RMAppAttemptEventType.LAUNCHED event |
RMAppState ACCEPTED -> ACCEPTED
1 | AttemptLaunchedTransition (update the launchTime and publish to ATS) |
RMAppAttemptState LAUNCHED -> RUNNING, RMAppState ACCETPTED -> RUNNING
1 | (AM) Application master (MRAppMaster) start |
Appliation master allocate resource from resource manager, start container by communicating with node manager, run map reduce tasks in the container
1 | (AM) |
YarnChild works and perform map tasks
1 | YarnChild.main |
Similar progress as above and reducer task starts, until job ends
1 | ...(omit some part)... |